As we just have shown you, using Ansible would require very little programing skills. Just understanding the structure of YAML data and understanding how to use Ansible is enough to configure elements of the ACI fabric. However, Ansible isn't the only option for that type of flexibility, since a similar tool: Terraform, can perform the same infrastructure build up also using YAML as a definition.
So where do you stand? Most network architects and operators are very familiar with finger defined networks. You have probably done TCL/Expect scripts over the years. If you have, you understand having to keep the scripts updated and you find yourself advancing more and more into the territory of regular expression headache to extract data that was intended for human visualization.
If you have been doing networking for 20 years, you understand this world well. You connect via tools like SecureCRT or Putty into the devices and issue commands to configure everything. You feel confortable in this area and you understand the flexibility. Yet you understand how more complex and difficult it is to configure hundreds of devices without making mistakes.
What we just showed you with Ansible. Enter some parameters and information and you can configure the devices. Maybe YAML is different for you and yet you still think you can understand some of it. See the potential but concerned with understanding how this will play out in production networks.
Hey Ansible is written in Python! Now you are getting more serious and want to learn to create some powerful scripts written directly to the ACI ReST interface.
The promised land. Where now the network operators enter some information into an application on a computer to make changes to the network like adding a compute node! Configuring new VLANS. These operators don't see the interface of ACI anymore, they are using the application you developed and they can easily get the process done. Low training, simple and to the point. Yet this requires a whole set of knowledge and capabilities that might not be for you! Or maybe you can convince management to hire a programer to develop such application
But it seems that business today are asking for more. Do more with less seems to be the mantra everywhere. How do you simplify operations? If you have to configure hundreds of switches, verify configurations, make sure that things are set as needed. For this, it seems that scripts in Python have become more and more prevalent and you can find many tools on the Internet. Yet, patching everything together could become complicated and it could take time.
So you might be asking the question, how does ACI help me? The answer is visible in
everything related to ACI. When you SSH into the APIC, spines or the leafs you are interacting
with the API. A simple show version is actually just doing a ReST API call into the
fabric controllers to get the information, the same applies for the leafs and spines.
Why is this important? Because this is what makes ACI unique in the market, the API is the foundation. Everything has to access it to accomplish tasks. In the past, many network equipment vendors layered the API over the operating system and it usually meant that not everything was available. This made the API limiting into what it could potentially do. Not with ACI as ACI was built from the ground up with the ReST API as to how the devices, user interface and internal interactions would happen. By going this route ACI achieves an important element: Access to the operations of the equipment can be achieved either through human interface elements such as the GUI and CLI or via the programatic method of its API.
So what is this REST API? If we look in Wikipedia we get: Representational state transfer (REST) is a software architectural style that was created to guide the design and development of the architecture for the World Wide Web. REST defines a set of constraints for how the architecture of an Internet-scale distributed hypermedia system, such as the Web, should behave. The REST architectural style emphasises the scalability of interactions between components, uniform interfaces, independent deployment of components, and the creation of a layered architecture to facilitate aching components to reduce user-perceived latency, enforce security, and encapsulate legacy systems.
REST has been employed throughout the software industry and is widely accepted set of guidelines for creating stateless, reliable web APIs. A web API that obeys the REST constraints is informally described as RESTful. RESTful web APIs are typically loosely based on HTTP methods to access resources via URL-encoded parameters and the use of JSON or XML to transmit data.
The REST architectural style is designed for network-based applications, specifically client-server applications. But more than that, it is designed for Internet-scale usage, so the coupling between the user agent (client) and the origin server must be as lightweight (loose) as possible to facilitate large-scale adoption. This is achieved by creating a layer of abstraction on the server by defining resources that encapsulate entities (e.g. files) on the server and so hiding the underlying implementation details (file server, database, etc.). But the definition is even more general than that: any information that can be named can be a resource: an image, a database query, a temporal service , or even a collection of other resources. This approach allows the greatest interoperability between clients and servers in a long-lived Internet-scale environment which crosses organisational (trust) boundaries.
One of the key elements of ReST is that it is stateless. In computing, a stateless protocol is a
communications protocol in which no session information is retained by the receiver, usually a server. Relevant session
data is sent to the receiver by the client in such a way that every packet of information transferred can be
understood in isolation, without context information from previous packets in the session. This property of
stateless protocols makes them ideal in high volume applications, increasing performance by removing server
load caused by retention of session information.
Let's dig a little deeper into what some of the terminology means:
The origin of the connection. The client will be running an operating system capable of reaching the server and use software to build the connection as defined by the user.
THe address that we are asking to reach. Contains the URL (Uniform resource locator) and the URN ( Uniform Resource Name). The combination of these two build the URI that is what is the address of what we are looking for. The combination of these gets us to the server and also to what we are asking of the server.
As you are probably aware this all happens over TCP.
The keeper of the information or action we are looking for in the request. The server simply responds back with what we are asking for. And once it provides the answer back, it considers the session completed. That is the stateless part.
Everytime you connect to an application on the internet, could be your financial institution, Amazon or Youtube, you are
downloading code into your browser that is in turn executing code back to the servers. Therefore, the Amazon
webpage loads, the included javascript code that is then executed upon completing the load to do tasks.
In the case of Amazon the HTML page provides the layout yet the javascript is the one
that is asking the server for information about what is interesting to you!. So if you
had browsed for a particular book, Amazon knows what to show you that might interest you more.
While the ACI fabric doesn't track what you are interested in, every browser click, every show command interacts with that REST interface to get the data and represent that data back to you.
So when you send the request to the server we have to wrap that request into different types. The
term used is verb. And this tells the server what we are wanting to do. If
you are just going to ask the server to send you information, then the GET verb
is what is mostly used. When you want to make changes, this usually includes sending a
payload with the request. This is called POST. For ACI what you will
mostly use are only going to GET and POST verbs.
| VERB | CRUD | Description |
|---|---|---|
| GET | Read | The GET verb is the most common verb and is used to retrieve information from the ReST server |
| POST | Create | The POST verb is mostly used for creation of a new entity or service on the the ReST server |
| PUT | Update/Replace | The PUT verb is utilized for updating resources in the ReST server API. |
| DELETE | Delete | As the name states, it deletes the specified resource that is invoked. |
For each request we have to build a complete URL. We can break down the URL as follows:
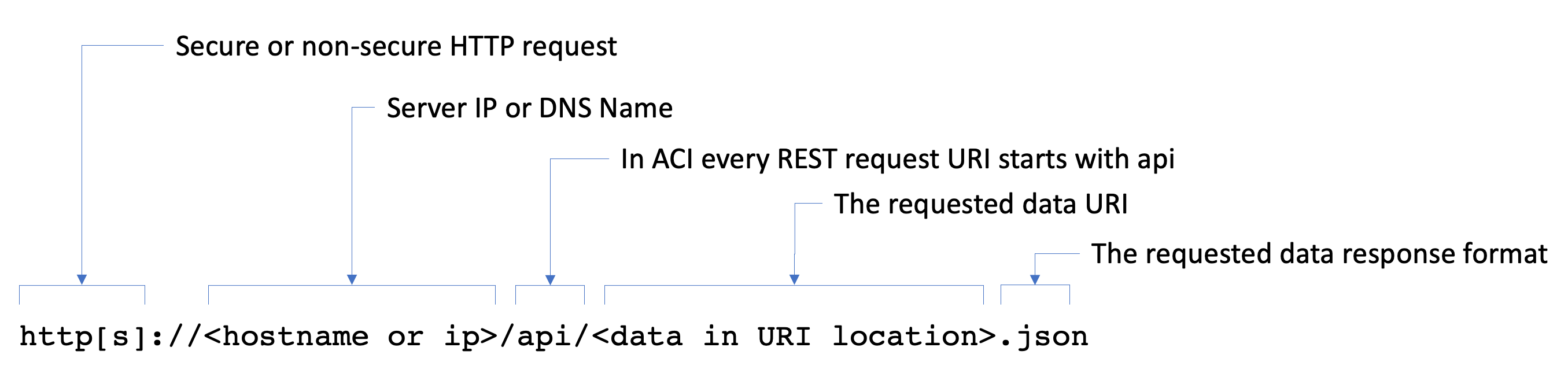
When we send a request to the server, the method is included. With the POST method data
is included in the request inside the body portion.
We can do a request to ACI asking to provide the list of Spines and Leafs in the fabric. The URL would look as follows:
https://10.0.226.41/api/node/class/dhcpClient.json
The response from the fabric is going to be a data structure that is known as an object. This is
known as an object because as a data structure it contains two distinct elements; arrays and key,value pairs. We
don't have to go into many details, but as you can see in the following object that is returned by
ACI it would be easy to identify certains aspects of this object.
{
"totalCount": "57",
"imdata": [
{
"dhcpClient": {
"attributes": {
"hwAddr": "00:00:00:00:00:00",
"id": "FDO21400SS1",
"ip": "10.9.88.66/32",
"model": "N9K-C93180YC-EX",
"name": "L4",
"nameAlias": "",
"nodeId": "204",
"nodeRole": "leaf",
"nodeType": "unspecified",
"podId": "1",
"runningVer": "n9000-15.2(4d)",
"supported": "yes"
}
}
},
]
}
If we need to get the ip of this particular switch in the fabric, we can reference this
in the code as dhcpClient.attributes.ip. You can see that we can also get
the version of software the switch is running, the model etc.
In the following diagram you can see further breakdown of that URL call.
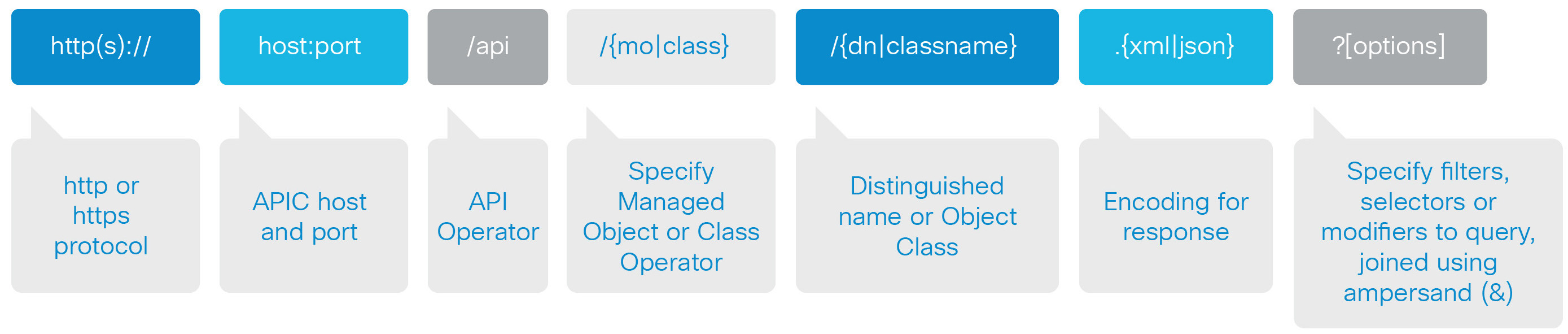
Which leads us into talking about the object model in ACI, also known as the MIT.
All the physical and logical components that comprise the Application Centric Infrastructure fabric are represented in a hierarchical management information model (MIM), also referred to as the MIT. Each node in the tree represents an MO or group of objects that contains its administrative state and its operational state.
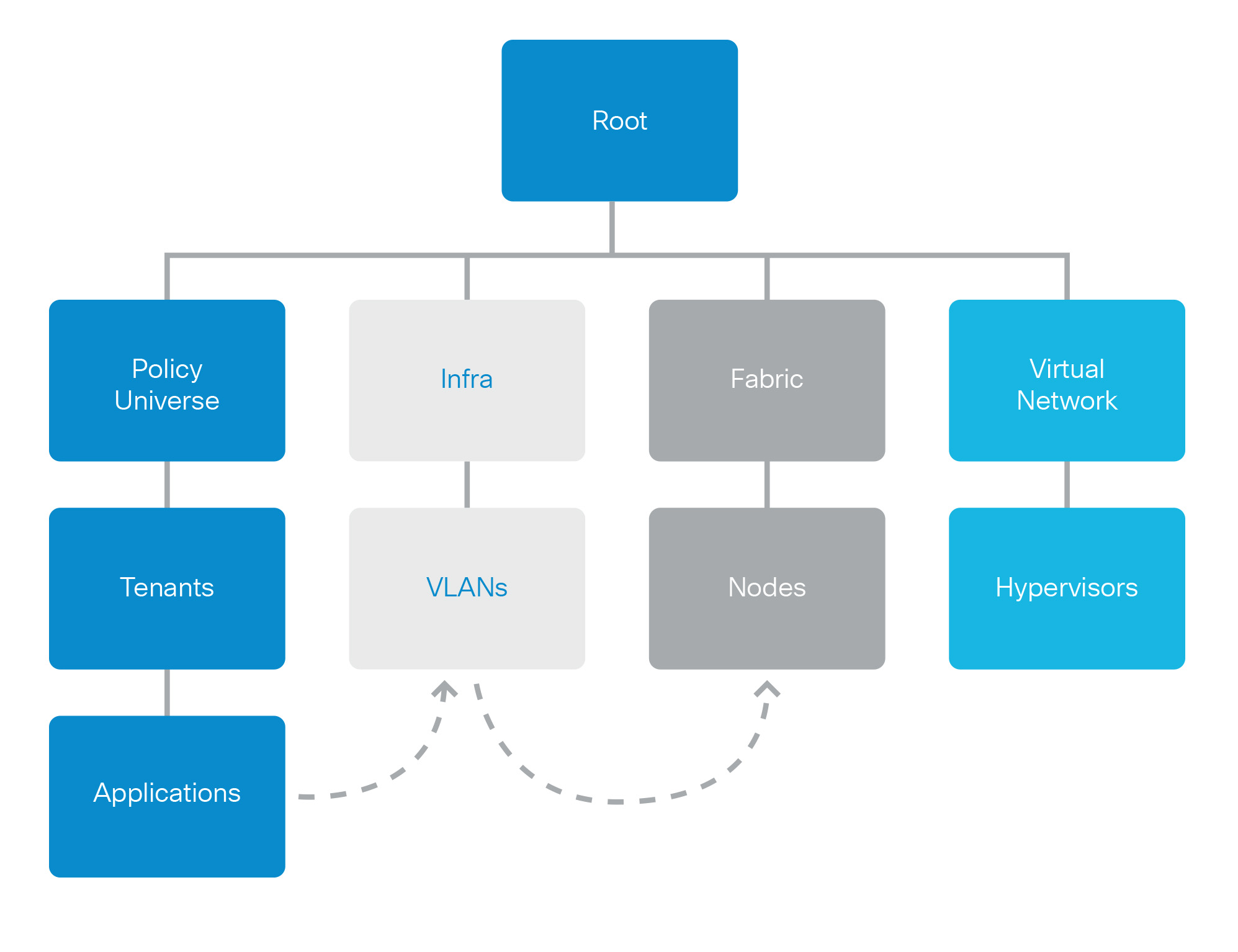
The hierarchical structure starts at the top (Root) and contains parent and child nodes. Each node in this tree is an MO and each object in the ACI fabric has a unique distinguished name (DN) that describes the object and its place in the tree. MOs are abstractions of the fabric resources. An MO can represent a physical object, also called a concrete object, such as a switch or adapter, or a logical object, also called an abstract object, such as a policy or fault.
The APIC represents the configuration and updates the logical model. The APIC then performs the intermediate step of creating a fully elaborated policy from the user policy and then pushes the policy into all the switch nodes where the concrete model is updated. The models are managed by multiple data management engine (DME) processes that run in the fabric. When a user or process initiates an administrative change to a fabric component (for example, when you apply a profile to a switch), the DME first applies that change to the information model and then applies the change to the actual managed endpoint. This approach is called a model-driven framework.
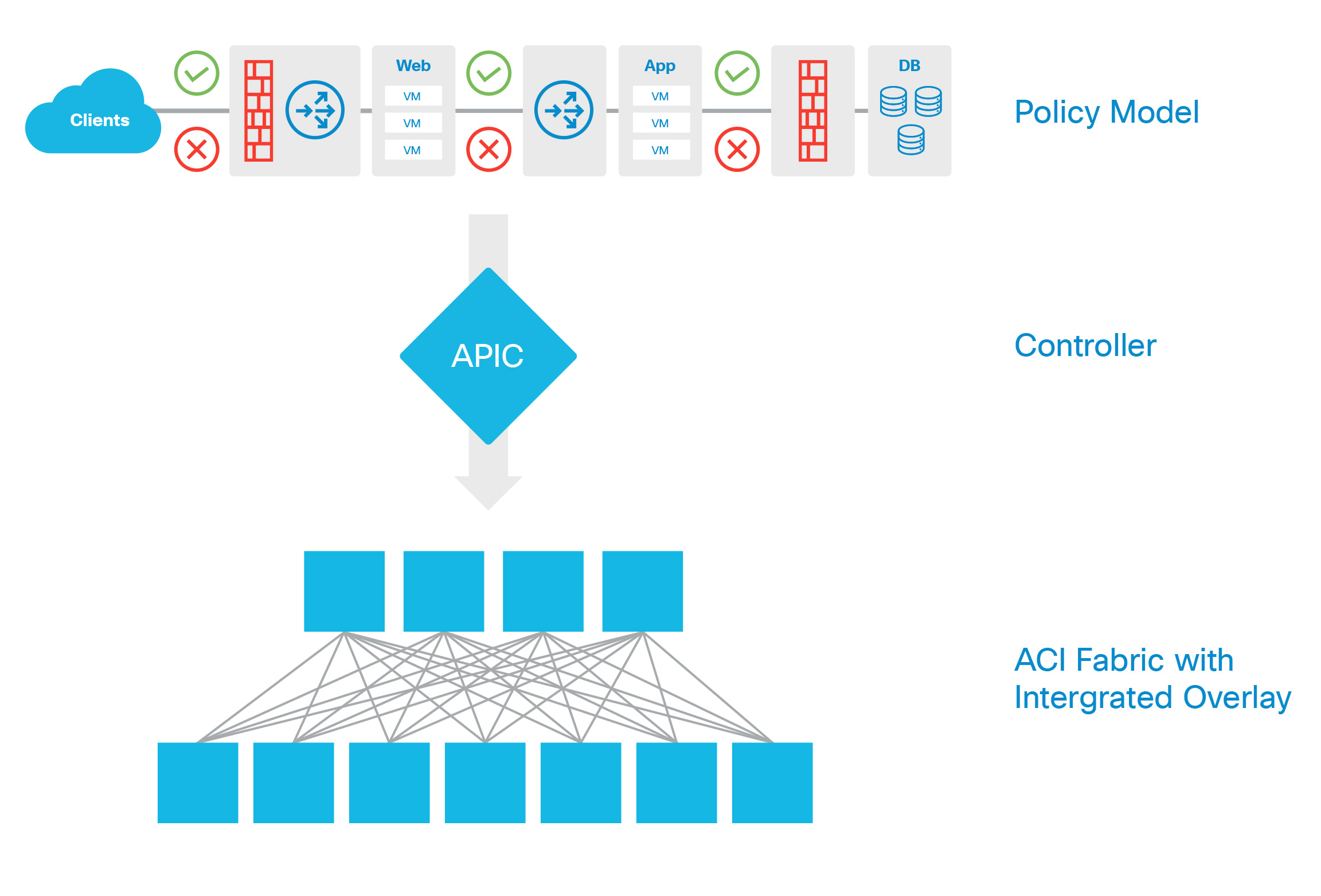
As shown in the diagram to the left, the logical policy model is built through manipulation of the MIT, either through direct GUI, programmatic API, or through traditional CLI methods. Once the policy is built, the intention of the policy gets resolved into an abstract model, then is conferred to the infrastructure elements. The infrastructure elements contain specific Cisco ASIC hardware that make them equipped, purpose-built agents of change that can understand the abstraction that the policy controller presents to it, and automate the relevant concrete configuration based on the abstract model.